Last Modified: 2023-Jul-19
Building a chatbot
Index of Contents
- OpenAI
- Local IA
- Thanks to LMSYS.ORG for making these kind of stuff https://lmsys.org/blog/2023-03-30-vicuna/
OpenAI
OpenAI offers a handful of utilities for chatbots For example, we could fed it our data from my tfg’s site then ask for conclusions about the data, even examples. Amazing response, indeed. As long as it’s public data, there shouldn’t be any concern, althought its api rate limits and costs might be too high.
Local IA
Using Llama.cpp, the same process can be done. There are simple models such as those of 3 or 7billions of parameters, which are good enough for fantasy😟 or social chats. These models, like vicuna, were trained with chagpt responses shared by users, that is the reason why these kinds of conversations are quite good for such tiny models.
Apparently the 65B model is much better, I did not test it.(potato laptop)
Chatgpt’s behaviour can be emulated with an scenario This is a transcript, at the start of the completion prompt (which can be added silently).
#To chatgpt's api, you send the conversation (role: assistant is what the model responds)
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
#To the /completion api of llama.cpp's server, you give the number of characters you want it
# to predict and the stop strings
{"prompt":"Transcript of a dialog where user interacts with an Assistant, named isalt.\nuser:",
"n_predict":500, "stop":["isalt:","user:"]}
For the good looking effect of inserting sequentially the tokens,stream can be set to true, in both the gpt’s api and llama.ccp’s. Which opens a connection that returns a token per line (\n), between empty lines.
{"prompt":"Transcript of a dialog where user interacts with an Assistant, named isalt.\nuser:",
"n_predict":500, "stop":["isalt:","user:"], "stream":true}
> {data:"Hi",...}
>
> {data:"I'm",...}
>
> {data:"an",...}
>
This behaviour is abstracted if you use a library like llamasharp or python’s openai package
PoC architecture
I’ve implemented a proof of concept with an asp backend.
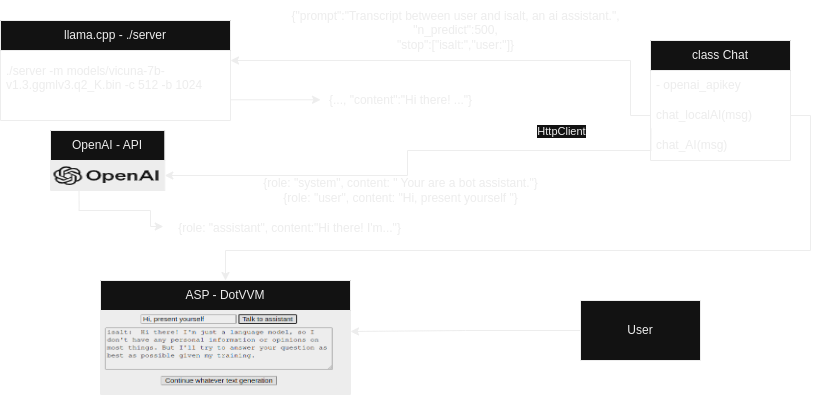
Conclusions:
- Using a very efficient 7b parameters model, tasks like redacting an email, interacting with a fantasy characters, etc. Give very chatgpt like results in tens of seconds.
- I didn’t have success with long prompts, tried replicating the website comprehension, but the model spewed nonsense, even reducing the size did not give results. Prompt engineering ftw?
- I need to research more about the parameters(frequency_penalty, top_k,etc) and to find more models 😀 gotta catch ‘em all.